Cognee - release v0.1.0¶
Preface¶
In a series of posts we explored issues with RAGs and the way we can build new infrastructure stack for the world of agent networks.
To borrow the phrase Microsoft used, to restate the problem:
- Baseline RAG performs poorly when asked to understand summarized semantic concepts holistically over large data collections or even singular large documents.
In the previous blog post we explained how developing a data platform and a memory layer for LLMs was one of our core aims.
To do that more effectively we turned cognee into a python library in order to make it easier to use and get inspiration from the OSS community.
Improved memory architecture¶
With the integration of Keepi.ai, we encountered several challenges that made us reassess our strategy. Among the issues we’ve identified were:
-
The decomposition of user prompts into interconnected elements proved overly granular, leading to data management difficulties on load and retrieval.
-
A recurring problem was the near-identical decomposition pattern for similar messages, which resulted in content duplication and an enlarged user graph. Our takeaway was that words and their interrelations represent only a fragment of the broader picture. We need to be able to guide the set of logical connections and make the system dynamic so that the data models can be adapted and adjusted to each particular use-case. What works for e-commerce transaction handling might not work for an AI vertical creating power point slides.
-
The data model, encompassing Long-Term, Short-Term, and Buffer memory, proved both limited in scope and rigid, lacking the versatility to accommodate diverse applications and use cases. Just collecting all elements from all memories seemed naive, while getting certain nodes with classifiers did not add enough value.
-
The retrieval of the entire buffer highlighted the need for improved buffer content management and a more adaptable buffer structure. We conceptualized the buffer as the analogue of human working memory, and recognize the need to better manage the stored data.
Moving forward, we have adopted several new strategies, features, and design principles:
Propositions:¶
Defined as atomic expressions within a text, each proposition encapsulates a unique factoid, conveyed in a succinct, standalone natural language format. We employ Large Language Models (LLMs) to break down text into propositions and link them, forming graphs with propositions as nodes and their connections as edges. For example, "Grass is green", and "2 + 5 = 5" are propositions. The first proposition has the truth value of "true" and the second "false". The inspiration was found in the following paper: https://arxiv.org/pdf/2312.06648.pdf
Multilayer Graph Network:¶
A cognitive multilayer networks is both a quantitative and interpretive framework for exploring the mental lexicon, the intricate cognitive system that stores information about known words/concepts.
Mental lexicon is component of the human language faculty that contains information regarding the composition of words.
Utilizing LLMs, we construct layers within the multilayer network to house propositions and their interrelations, enabling the interconnection of different semantic layers and the cross-layer linking of propositions. This facilitates both the segmentation and accurate retrieval of information.
For example, if "John Doe" authored two New York Times cooking articles, we could extract an "ingredients" layer when needed, while also easily accessing all articles by "John Doe".
We used concepts from psycholinguistics described here: https://arxiv.org/abs/1507.08539
Data Loader:¶
It’s vital that we address the technical challenges associated with Retrieval-Augmented Generation (RAG), such as metadata management, context retrieval, knowledge sanitization, and data enrichment.
The solution lies in a dependable data pipeline capable of efficiently and scalably preparing and loading data in various formats from a range of different sources. For this purpose, we can use 'dlt' as our data loader, gaining access to over 28 supported data sources.
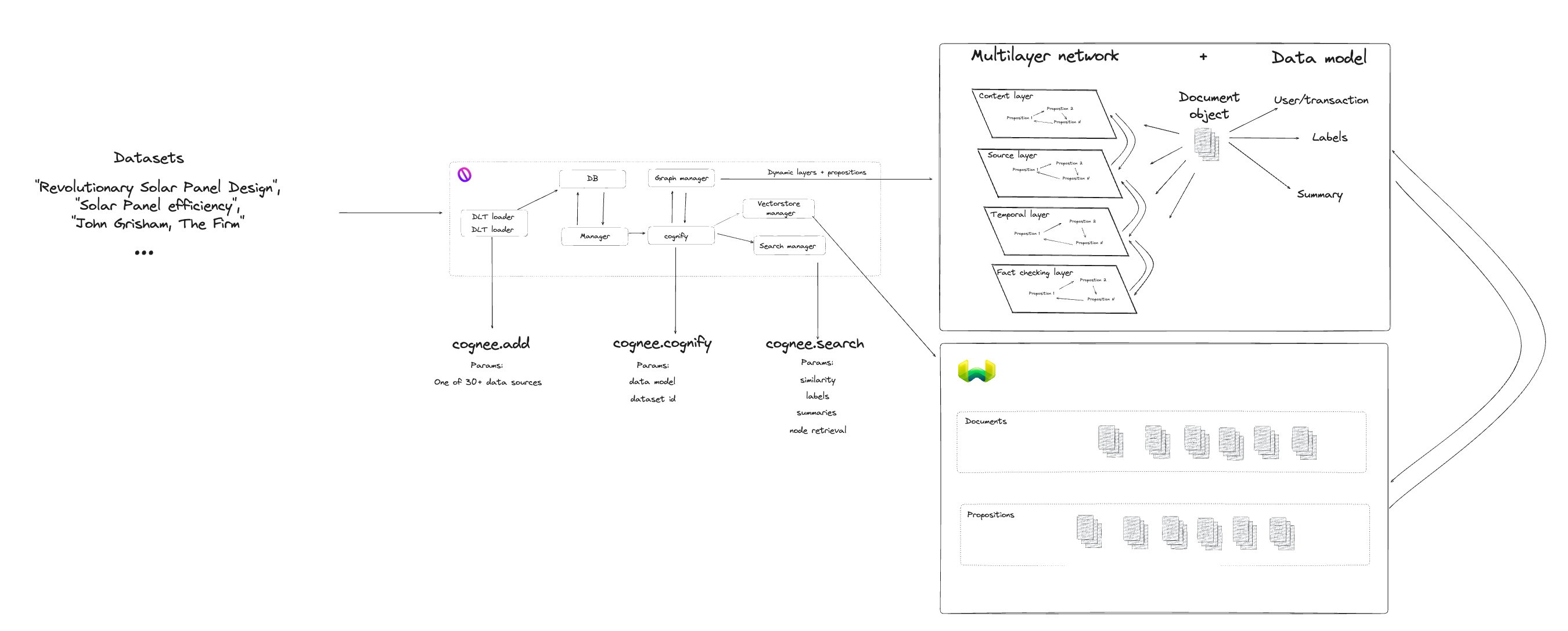
To enhance the Pythonic interface, we streamlined the use of cognee into three primary methods. Users can now execute the following steps:
- cognee.add(data): This method is used to input and normalize the data. It ensures the data is in the correct format and ready for further processing.
- cognee.cognify(): This function constructs a multilayer network of propositions, organizing the data into an interconnected, semantic structure that facilitates complex analysis and retrieval.
- cognee.search(query, method='default'): The search method enables the user to locate specific nodes, vectors, or generate summaries within the dataset, based on the provided query and chosen search method. We employ a combination of search approaches, each one relying on the technology implemented by vector datastores and graph stores.
Integration and Workflow¶
The integration of these three components allows for a cohesive and efficient workflow:
Data Input and Normalization:
Initially, Cognee.add is employed to input the data. During this stage, a dlt loader operates behind the scenes to process and store the data, assigning a unique dataset ID for tracking and retrieval purposes. This ensures the data is properly formatted and normalized, laying a solid foundation for the subsequent steps.
Creation of Multilayer Network:
Following the data normalization, Cognee.cognify takes the stage, constructing a multilayer network from the propositions derived from the input data. The network is created using LLM as a judge approach, with specific prompt that ask for creating of a set of relationships. This approach results in a set of layers and relationships that represent the document.
Data Retrieval and Analysis
The final step involves Cognee.search, where the user can query the constructed network to find specific information, analyze patterns, or extract summaries. The flexibility of the search function allows to search for content labels, summaries, nodes and also be able to retrieve data via similarity search. We also enable a combination of methods, which leads to getting benefits of different search approaches.
What’s next¶
We're diligently developing our upcoming features, with key objectives including:
- Adding audio and image support
- Improving search
- Adding evals
- Adding local models
- Adding dspy
To keep up with the progress, explore our implementation on GitHub and, if you find it valuable, consider starring it to show your support.